
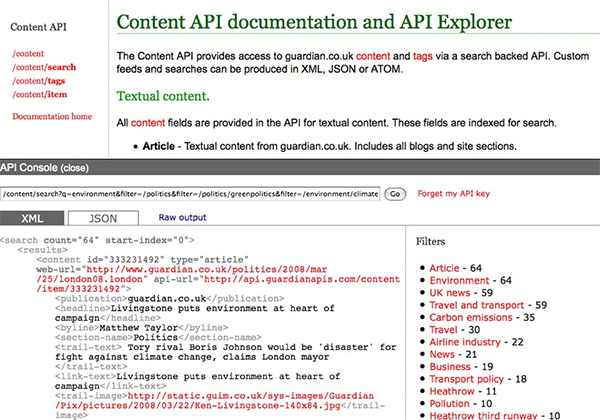
In the wake of the recently introduced , UK newspaper and news website has announced a competing API that allows third parties the opportunity to incorporate all material from the Guardian into their own sites for free, including over a million articles going back to 1999. In return for being able to use Guardian content in this way, third parties are expected to carry Guardian advertising, a requirement forming part of its terms of use (not yet, but in the nearby future).
The actual API the Guardian has developed consist of two components: and [guardian.co.uk]. The Open Platform will enable users to weave Guardian material, text, audio, video, and more, in online mash-ups, even commercial. In turn, Data Store offers access to about 80 data collections, which have been put together by the paper's editors. Their topics range from , over the , , or the .
Each Data Store dataset seems to be stored as a Google Spreadsheet, which means developers can access it using Google's I. (Note: for those interested in more publicly available datasets, it might be worth it to also look at the).
As a side note, point to the fact of The Guardian shareholder structure making this possible: "It helps that the paper is owned and run by a charitable trust which does not have shareholders who would normally have a heart attack at such a move."
Some early application examples include , which searches the database of Guardian articles and then proposes links to related concepts. There is also , an application to provide user-generated tagging on The Guardian content; , built by , designed to crowdsource geodata based on Guardian articles; and , which insert lists of articles from the Guardian about its sculptors into their biography and home pages.
Even more at , , .
UPDATE
Image taken from Roo Reynolds at .
 Time and Date follows Time Zone (Brussels)
Time and Date follows Time Zone (Brussels)